Heat Maps for Research Paper Topics and Impact
Overview
- A project with Lea Berrang-Ford, Priestley Chair in Climate and Health, Sustainability Research Institute (SRI) and Department for International development (DfID) looking at the mapping between topics and locations of research papers.
- Duration: 2 weeks
- CEMAC Output - To create an interactive web interface to visualise existing natural language processing work.
- Project URL: https://cemac.github.io/DIFID/ui/
Description:
As part of the DfID project papers are fed into a Natural Language Processing (NLP) algorithm to generate a set of weighted topics. As with all relational datasets, this format lends itself to be represented in a scale-free graph like structure, allowing us to see groupings of topics and locations of the papers.

Next the data is inserted in a force directed graph-like dimensionality reduction algorithm (t-distributed stochastic neighbour embedding). This generates a two dimensional embedding of papers with similar topics/locations/features allowing us to extract information about each topic.

Nodes within this interactive representation can then be filtered either by topic, or by geographical location (both of the authors, or the subject study.
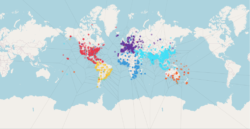
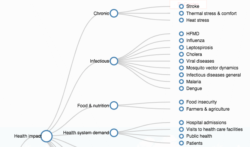
The live site is here: https://apsis.mcc-berlin.net/climate-health/
CEMAC Role
Summary -
The CEMAC role was to provide guidance and produce an interactive app with the following criteria:
- Visualise the global positions of each paper and study location
- Visualise the dimensionality reduced grouping of items
- Interactive zoom, item identification and filtering
- Selecting individual continents
- Filtering using a hierarchical topic tree
- Slider to isolate items with only strong relationships to a topic
- Linking data points to a download link for each paper
- Fuzzy matching for relevant papers
- Intuitive non-obfuscated region identification (using the t-SNE dataset)
- Using data within the format provided (no pre-processing)
- Potential scalability - the visualisation needs to still be responsive with millions of data points.
Skills Used